We would like to process more data faster, and our GPUs are able to calculate the full result by itself.
DDP - Distributed Data Parallel
We spawn multiple processes across machines, and a create a single instance of the model per process. DDP registers an autograd hook for each trainable parameter.
Note: If applying torch.compile, just apply the DDP Wrapper before the compile
Steps:
Broadcasts the local model's state_dict to all process
Each DDP Process creates a local Reducer that is responsible for syncing gradients in the backward pass. The Reducer uses the AllReduce Collective (Collective Operations). It organizers paramters into buckets. AllReduce will be triggered for a bucket once the gradients have been computed and while this is happening, we can continue with grads for the rest of params. Note, they are allocated into buckets in the reverse order.
DDP takes the input and does forward pass in the local model, and depending on the params, DDP could find all the unused parameters and then set them ready for reduction, immediately.
In the backward, with the aurograd hook attached to all the parameters, DDP will mark when a parameter becomes ready for Reduction. When all the parameters within a bucket become ready, it will fire off AllReduce, which will calculate the mean.
Then THe Oprimizer Step would just use the averaged gradients in all the local copies.
The performance advantage is due to overlapping allreduce collectives with backward computation. Therefore, we need to be able to break the backward graph, to experience this advantage, thus we need to use torchDynamo.
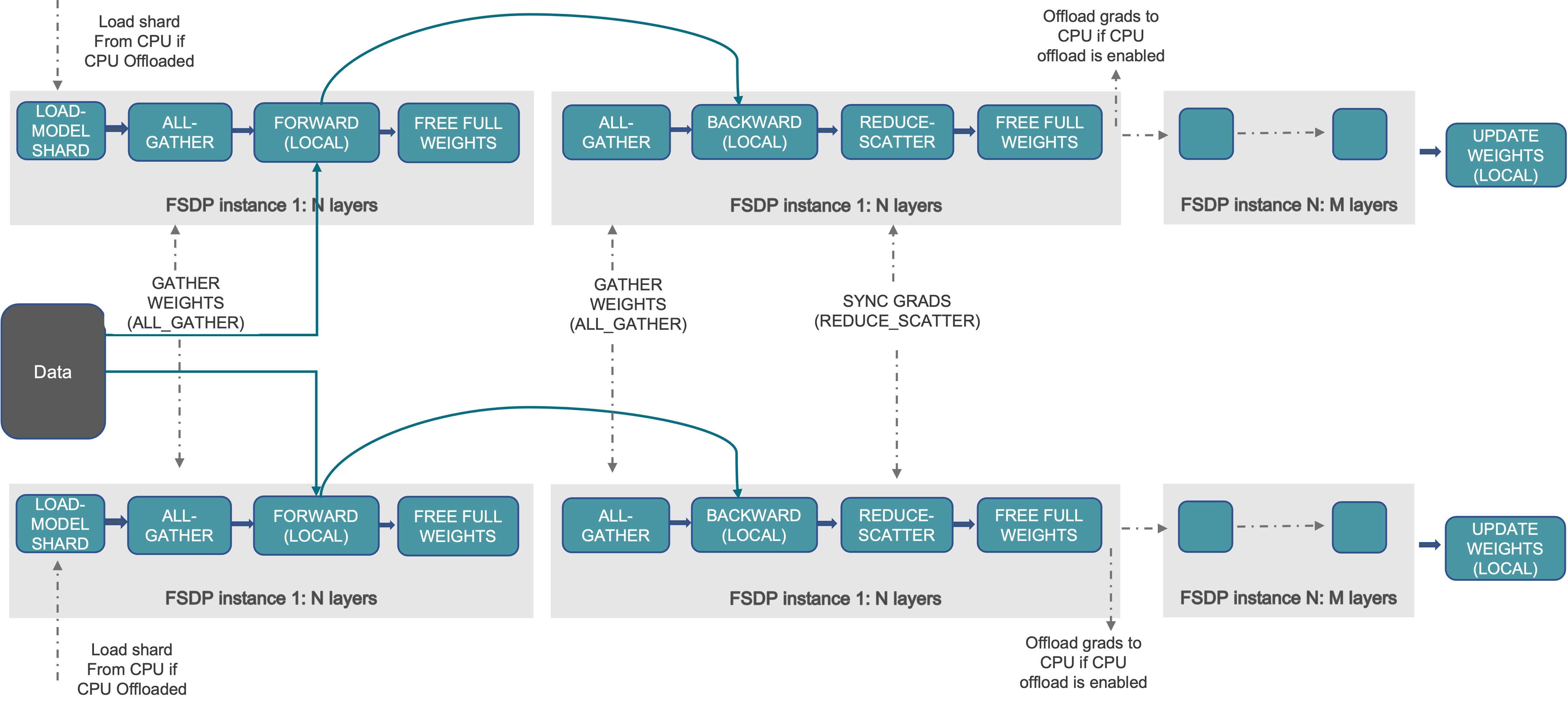
Fully Sharded Data Parallel (FSDP2)
FSDP Improves upon DDP by sharding the model parameters, In DDP, the model is replicated in storage and each models' computations are also replicated. However, in FSDP, the model is split in storage, but it's computations are still replicated. As long as the computations are replicated, it still falls under Data Parallelism.
Before the forward pass and the backward pass, all the machines gets all the weights and parameters which are initially sharded across machines.
Once the computation is done, you free the weights from machines, and in backward, you first gather the weights again, perform backward pass and then sync the gradients across the machines in which the data is sharded across. After this, you free the weights which you got from other machines.
If you do this, for all the machines across which the model parameters are sharded, you will be able to just update the weights locally at the end.
Tensor Parallelism
What if we can't fit even one of the model layers into a GPU memory? That's the problem Tensor Parallelism tries to solve.
Megatron-LM
The Paper[@shoeybiMegatronLMTrainingMultiBillion2020] deals with the large layers in the Transformer model.
MLP
First, let's look at the MLP layer.
The MLP corresponds to the following,