Ring, Ulysses and Unified Attention
How to handle long sequences by distributing the sequences across the multiple devices?
Ring and Ulysses are two standard approaches to solve this problem and combining them, you get Unified Attention.
Ring Attention
Introduced in [1]
Inspired by Blockwise Parallel Transformer (Introduced in [2]) , the distribute the blocks in a ring-like fashion.
Blockwise Parallel Transformer
Blockwise Computation of Self-Attention and Feedforward Network Fusion.
Algorithm
Given
- Input Sequence
- Number of query blocks
- Number of Key and Value Blocks
Then,
- Project Input Sequence to Query, Key and Value
- Split Query to
blocks - Split Key and Value Sequences into
blocks - Have a variable iterating from 1 to
.. lets call it - Choose the Corresponding Query Block.
- Compute the Attention for every Key and Value Blocks and record the normalization statistics
- Combine each blocks by scaling them to get the output for the corresponding query block
- Compute FeedForward on Attention Output
Basically the two key steps are recording normalization statistics and the scaling operation.
The Scaling Operation to Compute The Full Attention for a given Query Block is as follows:
After Computing the Attention for a Query Block, it can also perform the feedforward computation for each query block.
As you can see, it also includes the residual connection.
Ring Attention commonly uses P2P communication.
Coming Back to Ring Attention
Basically each device will have a separate block of query and key and value.
Ring Attention distributes the outer loop of computing blockwise attention among different hosts, with each device managing its respective input block.
How do the hosts get access to the other Key Value Blocks needed to compute the inner loop? Each devices send a copy of its key-value block to the next connected device and all the connected device form a ring. We are allowed to do this, because the operation within the inner loop is permutation invariant.
As long as the computation times exceeds the time required to transfer a key-value block between hosts, there is no additional overhead.

DeepSpeed Ulysses
Partitions along the head dimension among the devices instead of the sequence dimension. It was introduced in [3]
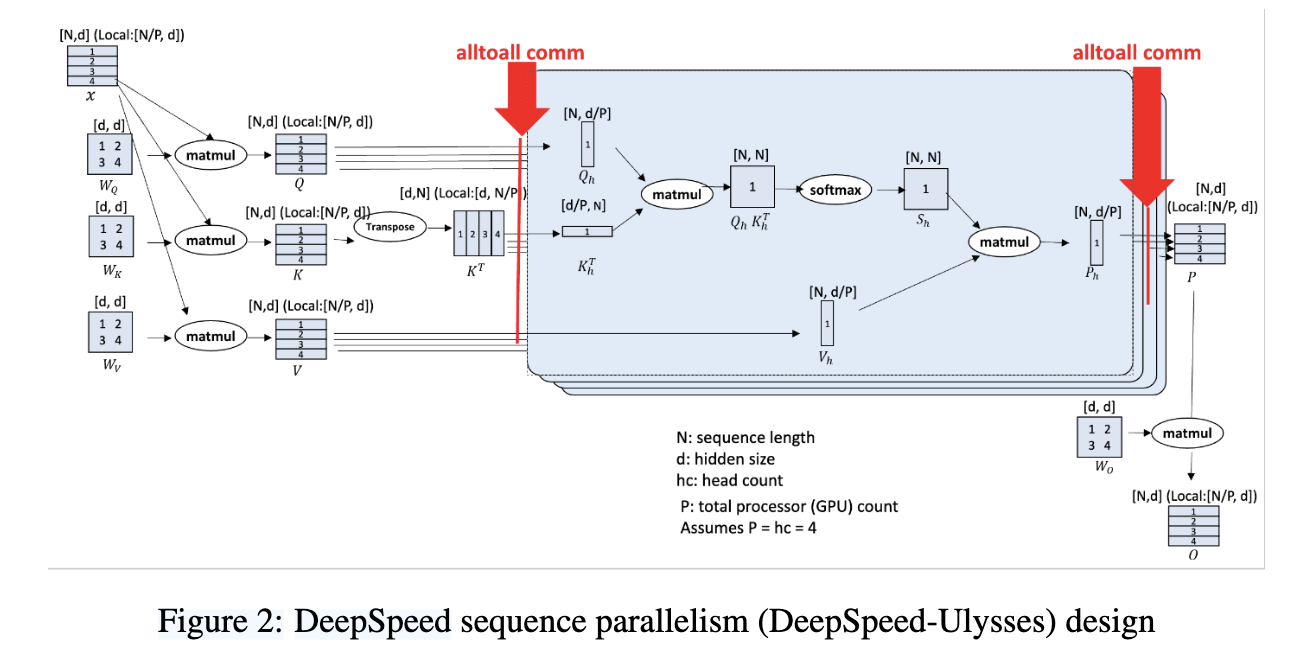
(Image taken from [3])
As the attention computation is independent w.r.t the heads, there isn't any changes to the calculation of the attention itself.
However, we are constrained by the number of heads. To Partition and Gather all the tensors, AllToAll Communication is used.
Unified Attention
Introduced in [4]
Unified Attention arranges the devices in a 2D mesh, with the columns serving as the Ring Groups and the Rows Serving as the Ulysses Group Dimension.
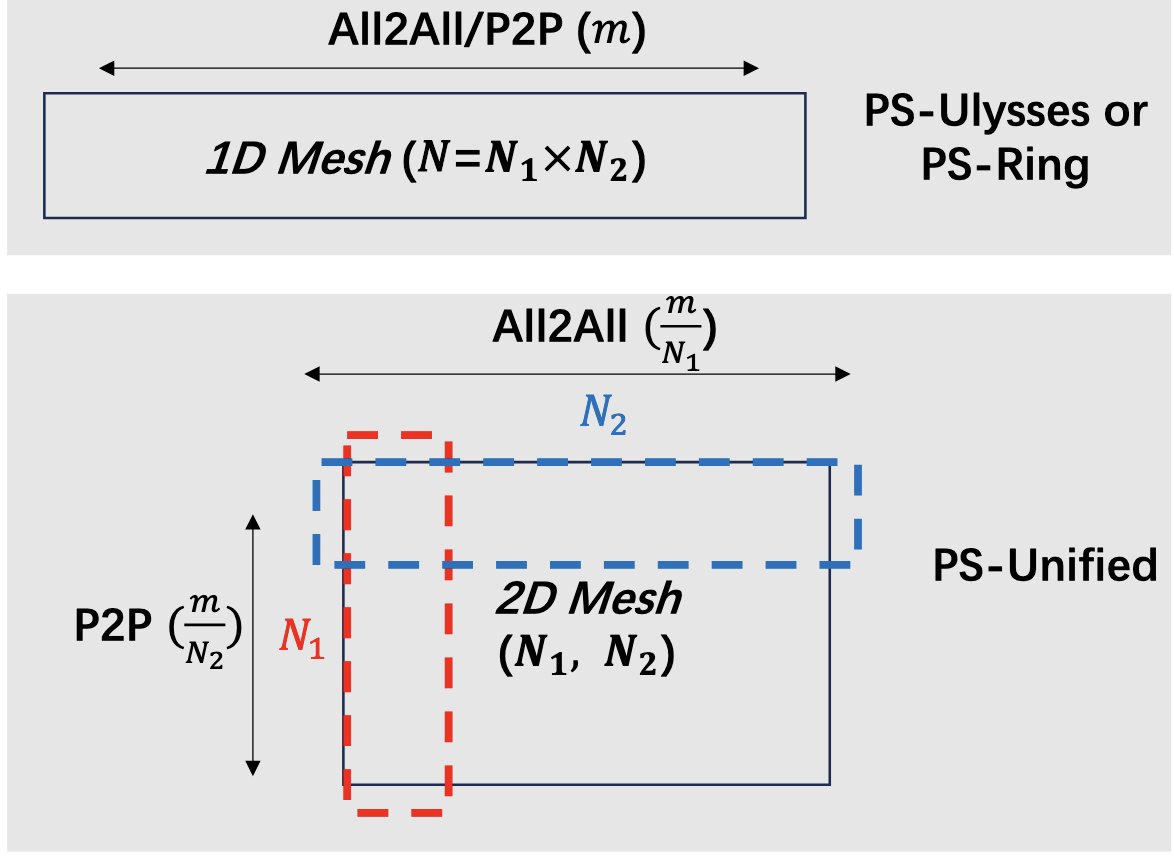
(Image from [4])
Basically, before we apply ring attention, apply an AllToAll(To Know more about the collectives, look into Collective Operations) with the Query, Key and Value Vectors. This would make sure that each device would get a tensor with the whole sequence and partitioned across the head dimension. Then Apply the Ring Attention with the devices in the same group

(Image from [4])
When applying a Causal Mask, if the sequence dimension is divided evenly among different GPUs, then some GPUs will get less tokens compared to the others.
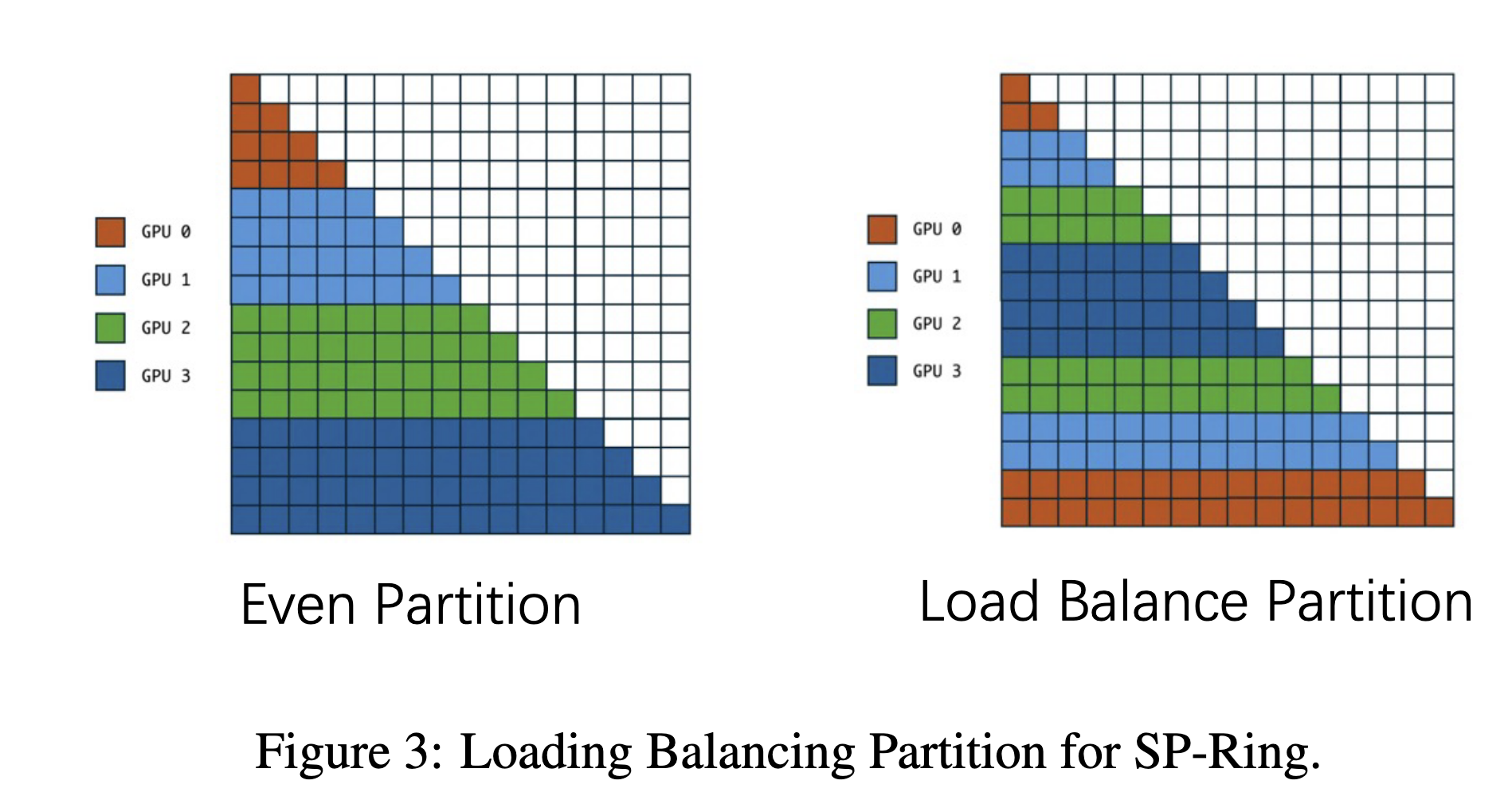
(Image from [4])
Thus, we have to partition as shown above.

(Image from [4])
You dont have to split it with just GPU Devices, you can also split it within different clusters and can use Ring Attention across Clusters like shown below:
References
[1]
H. Liu, M. Zaharia, and P. Abbeel, “Ring Attention with Blockwise Transformers for Near-Infinite Context,” Nov. 27, 2023, arXiv: arXiv:2310.01889. doi: 10.48550/arXiv.2310.01889.
[2]
H. Liu and P. Abbeel, “Blockwise Parallel Transformer for Large Context Models,” Aug. 28, 2023, arXiv: arXiv:2305.19370. doi: 10.48550/arXiv.2305.19370.
[3]
S. A. Jacobs et al., “DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models,” Oct. 04, 2023, arXiv: arXiv:2309.14509. doi: 10.48550/arXiv.2309.14509.
[4]
Fang, Jiarui, and Shangchun Zhao. "Usp: A unified sequence parallelism approach for long context generative ai." arXiv preprint arXiv:2405.07719 (2024).